



A、 多对一
B、 一对多
C、 多对多
D、 一对一
答案:C


A、 多对一
B、 一对多
C、 多对多
D、 一对一
答案:C


A. 冒泡排序为n/2
B. 冒泡排序为n
C. 快速排序为n
D. 快速排序为n(n-1)/2
A. 其他三项都不对
B. C(C#,Cn,P#)
C. SC(S#,C#,G)
D. S(S#,Sn,Sd,Dc,SA、
解析:首先,我们来解析这道题目。题目给出了三个关系模式:学生S、课程C、选课SC。学生S包含学号、姓名、所在系、所在系的系主任、年龄等属性;课程C包含课程号、课程名、先修课等属性;选课SC包含学号、课程号和成绩等属性。
题目要求找出包含对非主属性部分依赖的关系,即非主属性部分依赖于关系的某一部分属性,而不是整个主属性。根据关系模式S,我们可以看到属性Dc(所在系的系主任)对于属性Sn(学生姓名)是部分依赖的,因为学生姓名并不完全依赖于所在系的系主任,而是依赖于学号。因此,答案是D。
接下来,让我们通过一个生动有趣的例子来帮助你更好地理解这个知识点。假设你是一名学生,你的学号是001,你所在的系是计算机系,系主任是张老师。在关系模式S中,学生姓名Sn并不完全依赖于系主任Dc,因为不同的学生可能在同一个系里,但系主任是不同的。因此,学生姓名Sn部分依赖于学号S#,而不是所在系的系主任Dc。这就是非主属性部分依赖的概念。
A. 一对一
B. 多对多
C. 多对一
D. 一对多
A. R={(1,2),(2,3),(3,4),(4,5),(6,5)}
B. R={(1,2),(2,3),(6,5),(3,6),(5,4)}
C. R={(5,4),(3,4),(3,2),(4,3),(5,6)}
D. R={(1,2),(2,3),(4,3),(4,5),(5,6)}
A. 各模块应包括尽量多的功能
B. 各模块的规模应尽量大
C. 各模块之间的联系应尽量紧密
D. 模块内具有高内聚度、模块间具有低耦合度
解析:在结构化程序设计中,模块划分的原则是模块内具有高内聚度、模块间具有低耦合度。这意味着一个模块内部的功能相关性应该很高,模块之间的联系应该尽量减少,以便提高程序的可维护性和可扩展性。
举个例子来说,假设我们要设计一个学生管理系统,可以将系统划分为学生信息管理模块、课程管理模块、成绩管理模块等。这些模块内部应该包含相关的功能,比如学生信息管理模块应该包括学生的基本信息、课程管理模块应该包括课程的信息等。而模块之间的联系应该尽量减少,比如学生信息管理模块和课程管理模块之间应该通过接口进行通信,而不是直接调用对方的函数。
通过保持模块内的高内聚度和模块间的低耦合度,我们可以更好地组织程序结构,提高代码的可读性和可维护性,同时也方便后续的扩展和修改。因此,选项D是正确的答案。
 的结果为
的结果为
A. (a,a,2,2)
B. (c,c,11,4)
C. (b,e,1,2)
D. 空
A. 数据库系统可以减少数据冗余和增强数据独立性,而文件系统不能
B. 数据库系统能够管理各种类型的文件,而文件系统只能管理程序文件
C. 数据库系统可以管理庞大的数据量,而文件系统管理的数据量较少
D. 以上选项都不正确
A. 快速排序也适用于线性链表
B. 链表只能是非线性结构
C. 链表可以是线性结构也可以是非线性结构
D. 对分查找也适用于有序链表
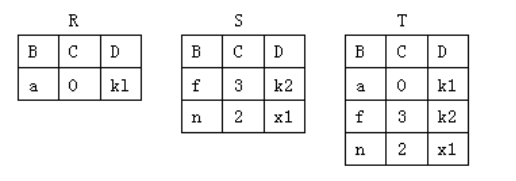 由关系R和S得到关系T,则所使用的操作为()
由关系R和S得到关系T,则所使用的操作为()
A. 并
B. 自然连接
C. 笛卡尔积
D. 差
A. 冒泡排序
B. 快速排序
C. 简单插入排序
D. 堆排序

