


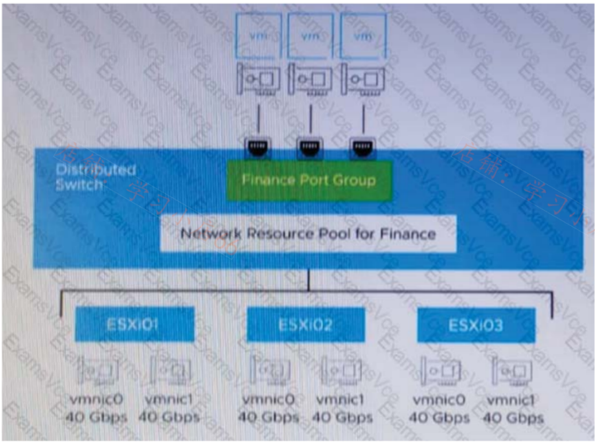
 An administrator set up the following configuration: • The distributed switch has three ESXi hosts, and each host has two 40 Gbps NICs.• The amount of bandwidth reserved for virtual machine (VM) traffic is 6 Gbps.The administrator wants to guarantee that VMs in the Finance distributed port group can access 50 percent of the available reserved bandwidth for VM traffic. k Given this scenario, what should the size (in Gbps) of the Finance network resource pool be?
An administrator set up the following configuration: • The distributed switch has three ESXi hosts, and each host has two 40 Gbps NICs.• The amount of bandwidth reserved for virtual machine (VM) traffic is 6 Gbps.The administrator wants to guarantee that VMs in the Finance distributed port group can access 50 percent of the available reserved bandwidth for VM traffic. k Given this scenario, what should the size (in Gbps) of the Finance network resource pool be?
A、18
B、80
C、36
D、120
E、
F、
G、
H、
I、
J、
答案:A
解析:解析:The size of the Finance network resource pool should be 50 percent of the reserved bandwidth for VM traffic, which is 6 Gbps x 3 hosts = 18 Gbps.财务网络资源池的大小应为虚拟机流量预留带宽的50%,即6 Gbps x 3台主机= 18 Gbps。

 An administrator set up the following configuration: • The distributed switch has three ESXi hosts, and each host has two 40 Gbps NICs.• The amount of bandwidth reserved for virtual machine (VM) traffic is 6 Gbps.The administrator wants to guarantee that VMs in the Finance distributed port group can access 50 percent of the available reserved bandwidth for VM traffic. k Given this scenario, what should the size (in Gbps) of the Finance network resource pool be?
An administrator set up the following configuration: • The distributed switch has three ESXi hosts, and each host has two 40 Gbps NICs.• The amount of bandwidth reserved for virtual machine (VM) traffic is 6 Gbps.The administrator wants to guarantee that VMs in the Finance distributed port group can access 50 percent of the available reserved bandwidth for VM traffic. k Given this scenario, what should the size (in Gbps) of the Finance network resource pool be?
A、18
B、80
C、36
D、120
E、
F、
G、
H、
I、
J、
答案:A
解析:解析:The size of the Finance network resource pool should be 50 percent of the reserved bandwidth for VM traffic, which is 6 Gbps x 3 hosts = 18 Gbps.财务网络资源池的大小应为虚拟机流量预留带宽的50%,即6 Gbps x 3台主机= 18 Gbps。


A. Storage Policy Based Management
B. Storage I/O Control
C. vSphere Storage APIs for Storage Awareness (VASA)
D. vSphere Distributed Resource Scheduler (DRS)
A. Host Connection Lost
B. Lost Network Path Redundancy
C. Lost Network Connectivity
D. Lost Storage Connectivity
解析:解析: Complicated, the question does not comment on whether the path is redundant, if not redundant the correct answer would be D, but if we take into account good practices, the FC would be redundant. 这个问题很复杂,没有评论路径是否冗余,如果不冗余,正确答案应该是D,但是如果我们考虑好的实践,FC将是冗余的。Book course: 6-23 Fibre Channel SAN Components Using SAN switches, you can set up path redundancy to address any path failures from host server to switch, or from storage array to switch. 6-25 Multipathing with Fibre Channel By default, ESXi hosts use only one path from a host to a given LUN at any one time. If the path actively being used by the ESXi host fails, the server selects another available path.书籍课程:6-23光纤通道SAN组件使用SAN交换机,您可以设置路径冗余来解决从主机服务器到交换机或从存储阵列到交换机的任何路径故障。6-25光纤通道多路径默认情况下,ESXi主机在任何时候都只使用一条从主机到给定LUN的路径。如果ESXi主机当前使用的路径出现故障,服务器会选择另一条可用路径。
A. A preferential rule between the DB group and PROD11 group
B. A preferential rule between the DB group and the PROD55 group
C. A preferential rule between the DB group and the PROD55 group
D. A required rule between the DB group and the PROD11 group
E.
F.
G.
H.
I.
J.
解析:解析:Option A is correct because it allows the administrator to create a preferential rule between the DB group and PROD11 group, which will force the VMs in the DB group to run on the hosts in the PROD11 group if possible, but will allow them to run on the hosts in PROD55 group if necessary. Option B is incorrect because it will create a preferential rule between the DB group and PROD55 group, which will force the VMs in the DB group to run on the hosts in PROD55 group if possible, which is not what the administrator wants. Option C is incorrect because it is the same as option B. Option D is incorrect because it will create a required rule between the DB group and PROD11 group, which will force the VMs in the DB group to run only on the hosts in PROD11 group and not allow them to run on the hosts in PROD55 group if needed.选项A是正确的,因为它允许管理员在DB组和PROD11组之间创建一个优先规则,如果可能,该规则将强制DB组中的虚拟机在PROD11组中的主机上运行,但如果必要,将允许它们在PROD55组中的主机上运行。选项B是不正确的,因为它将在数据库组和PROD55组之间创建一个优先规则,如果可能的话,将强制数据库组中的虚拟机在PROD55组中的主机上运行,这不是管理员想要的。选项C不正确,因为它与选项b相同。选项D不正确,因为它将在数据库组和PROD11组之间创建一个必需的规则,该规则将强制数据库组中的虚拟机仅在PROD11组中的主机上运行,而不允许它们在需要时在PROD55组中的主机上运行。
A. Add the user to the VM_Users group and leave the permissions on the virtual machine object unchanged
B. Add a new permission on the virtual machine object selecting the user and the new custom role.
C. Edit the Read Only role to add the Virtual Machine Snapshot Management privileges.
D. Create a new custom role with the Virtual Machine Snapshot Management privileges.
E. new permission on the virtual machine object selecting the VM_Viewers group and the new custom
F.
G.
H.
I.
J.
解析:解析: The administrator should create a new custom role with the Virtual Machine Snapshot Management privileges, which allows the user to create, delete and revert snapshots. The administrator should then add a new permission on the virtual machine object selecting the user and the new custom role, which grants the user the additional access required without affecting other users or groups。管理员应该创建一个具有虚拟机快照管理权限的新自定义角色,该角色允许用户创建、删除和恢复快照。然后,管理员应该在虚拟机对象上添加新的权限,选择用户和新的自定义角色,这将授予用户所需的额外访问权限,而不会影响其他用户或组
A. Generate a combined log bundle for all ESXI hosts using the vCenter Management Interface
B. Generate a separate log bundle for each ESXI host using the vSphere Host Client.
C. Generate a combined log bundle for all ESXI hosts using the vSphere Client.
D. Generate a separate log bundle for each ESXI host using the vSphere Client.
E. Generate a separate log bundle for each ESXI host using the vCenter Management Interface.
F. Generate a combined log bundle for all ESXi hosts using the vSphere Host Client.
G.
H.
I.
J.
解析:解释选项B、C和D是正确的,因为它们是为使用不同接口的单个或多个ESXi主机生成日志包的有效方法。选项A和E不正确,因为它们不是使用vCenter管理界面为所有ESXi主机生成日志包的可能选项。选项F不正确,因为不可能使用vSphere Host Client为所有ESXi主机生成组合日志捆绑包。
A. Update all Tanzu Kubernetes Grid clusters to the latest version prior to the Supervisor cluster update.
B. No action is needed - Tanzu Kubernetes Grid clusters will be updated automatically as part of the update process.
C. No action is needed - Incompatible Tanzu Kubernetes Grid clusters can be manually updated after the Supervisor cluster update.
D. Update incompatible Tanzu Kubernetes Grid clusters prior to the Supervisor cluster update.
解析:解析:Option D is correct because it indicates that the administrator must update incompatible Tanzu Kubernetes Grid clusters prior to the Supervisor cluster update, as this will ensure that there are no compatibility issues or disruptions during or after the update process. Option A is incorrect because it is not necessary to update all Tanzu Kubernetes Grid clusters to the latest version prior to the Supervisor cluster update, as some clusters may already be compatible with the new version. Option B is incorrect because Tanzu Kubernetes Grid clusters will not be updated automatically as part of the update process, as they require manual intervention from the administrator. Option C is incorrect because incompatible Tanzu Kubernetes Grid clusters cannot be manually updated after the Supervisor cluster update, as they may become inaccessible or unstable due to compatibility issues.选项D是正确的,因为它表明管理员必须在管理集群更新之前更新不兼容的Tanzu Kubernetes网格集群,因为这将确保在更新过程中或之后没有兼容性问题或中断。选项A是不正确的,因为没有必要在管理集群更新之前将所有Tanzu Kubernetes网格集群更新到最新版本,因为一些集群可能已经与新版本兼容。选项B是不正确的,因为Tanzu Kubernetes网格集群不会在更新过程中自动更新,因为它们需要管理员的手动干预。选项C是不正确的,因为不兼容的Tanzu Kubernetes网格集群在管理集群更新之后不能被手动更新,因为它们可能由于兼容性问题而变得不可访问或不稳定。If a Tanzu Kubernetes Grid cluster is incompatible with vSphere 8, upgrade the cluster before proceeding with the system upgrade.如果Tanzu Kubernetes网格集群与vSphere 8不兼容,请在继续系统升级之前升级该集群。
A. Configure VMware Cloud Disaster Recovery (VCDR) and combine it with array-based storage replication
B. Configure VMware a Site Recovery Manager and combine it with vSphere Replication
C. Configure a subscribed content library on the secondary site.
D. Configure VMware Site Recovery Manager and combine it with array-based storage replication
E.
F.
G.
H.
I.
J.
解析:
A. 75 percent of the capacity over a 30 second period
B. 60 percent of the capacity over a 30 second period
C. 60 percent of the capacity over a 40 second period
D. 75 percent of the capacity over a 40 second period
解析:解析: The distributed switch calculates uplinks for virtual machines by taking their port ID and the number of uplinks in the NIC team. The distributed switch tests the uplinks every 30 seconds, and if their load exceeds 75 percent of usage, the port ID of the virtual machine with the highest I/O is moved to a different uplink. 分布式交换机通过获取虚拟机的端口ID和NIC组中的上行链路数量来计算虚拟机的上行链路。分布式交换机每30秒测试一次上行链路,如果其负载超过使用率的75 %,具有最高I/O的虚拟机的端口ID将被移至不同的上行链路。
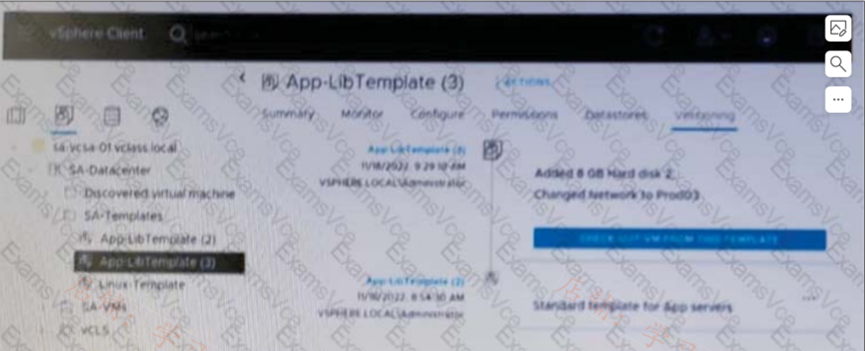 Given the configuration shown in the exhibit, what should the administrator do if the latest VM template contains changes that are no longer needed?
Given the configuration shown in the exhibit, what should the administrator do if the latest VM template contains changes that are no longer needed?
A. Delete App-LibTemplate (2)
B. Revert to App-LibTernplate (2)
C. Delete App-LibTemplate (3)
D. Check out App-LibTemplate (3)
解析:解析: Deleting App-LibTemplate (3) will remove the changes that are no longer needed and revert to the previous version of the template.删除App-LibTemplate (3)将删除不再需要的更改,并恢复到模板的前一版本。
A. Predictive DRS
B. vSphere HA Orchestrated Restart
C. vSphere HA Restart Priority
D. Proactive HA
解析:解析: An administrator is tasked with applying updates to a vSphere cluster running vSAN using vSphere Lifecycle Manager. Downtime to the ESXI hosts must be minimal while the work Is completed. I he administrator has already completed the following steps and no errors have been returned:管理员的任务是使用vSphere Lifecycle Manager向运行vSAN的vSphere集群应用更新。工作完成时,ESXI主机的停机时间必须尽可能短。如果管理员已经完成了以下步骤,并且没有返回任何错误:• Downloaded all applicable software and created a new Image .• Attached the new Image to the cluster and run a compliance check against the Image for the cluster .• Ran a remediation pre-check for the cluster.下载了所有适用的软件并创建了新的映像.将新映像连接到集群,并针对集群的映像运行合规性检查.为集群运行补救预检查.


