


答案:(1) 嵌套
解析:答案解析:


答案:(1) 嵌套
解析:答案解析:


A. 两个数组
B. 三个数组
C. 一个数组
D. 四个数组
A. numpy.load()
B. numpy.genfromtxt()
C. numpy.loadtxt()
D. numpy.fromtxt()
A. d = {}print(d)
B. d = dict()print(d)
C. d = ()print(d)
D. d = set()print(d)
A. names. append('Helen', 'Mary')
B. names.remove(1)
C. names.index('Jack')
D. names[2]='Jack'
A. 对
B. 错
A. 收费使用
B. 跨平台
C. 可拓展
D. 可嵌入
A. ls = [25, 13, 36, 1]ls.remove(13)print(ls)
B. ls = [25, 13, 36, 1]ls.pop(1)print(ls)
C. ls = [25, 13, 36, 1]ls.clear(13)print(ls)
D. ls = [25, 13, 36, 1]ls=[ls[0]]+ls[2:]print(ls)
A. 8 2
B. 8,2
C. 8 3 2
D. 8,3,2
解析:答案解析:
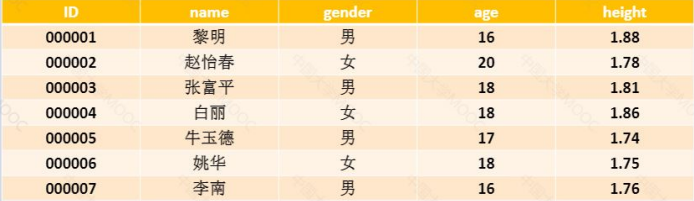 对以上数据,以性别字段作为分组依据,并对分组后的数据重新排序的语法正确的是()
对以上数据,以性别字段作为分组依据,并对分组后的数据重新排序的语法正确的是()
A. frame[['ID']].groupby(frame('gender')).count().sortⱣⱤvalues(by=('gender'))
B. frame[['ID']].groupby(['gender']).count().sortⱣⱤvalues(by=frame['gender'])
C. frame[['ID']].groupby(('gender')).count().sortⱣⱤvalues(by=frame('gender'))
D. frame[['ID']].groupby(frame['gender']).count().sortⱣⱤvalues(by=['gender'])
解析:答案解析:
A. d = {'北京': 2030, '上海': 2200, '天津': 1985, '重庆': 3325}print(d.('上海'))
B. d = {'北京': 2030, '上海': 2200, '天津': 1985, '重庆': 3325}print(d['上海'])
C. d = {'北京': 2030, '上海': 2200, '天津': 1985, '重庆': 3325}print(d.get('上海'))
D. d = {'北京': 2030, '上海': 2200, '天津': 1985, '重庆': 3325}print(d.get['上海'])


