


A、 内饰件
B、 外饰件
C、 功能件
D、 已上全都是
答案:D


A、 内饰件
B、 外饰件
C、 功能件
D、 已上全都是
答案:D


A. 成本较低、移动灵活。
B. 抓地力强、越障性能好。
C. 运动速度高、运动噪声小。
D. 负重性能好、相比于轮式底盘与腿足式底盘耗能小。
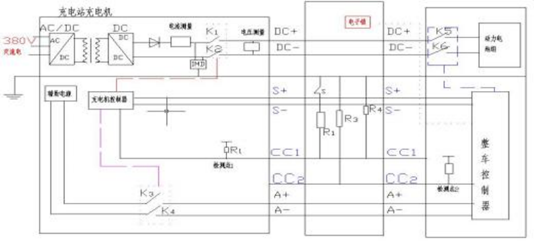
A. 1
B. 2
C. 3
D. 4
A. 有两套驱动系统
B. 配置发动机输出的动力仅用于推动发电机发电
C. 电池对发电机产生的能量和电动机需要的能量进行调节
D. 有两个电机
A. 50cm(厘米)
B. 40cm(厘米)
C. 30cm(厘米)
D. 20cm(厘米)
A. 串联式混合动力汽车
B. 并联式混合动力汽车
C. 外接充电型混合动力汽车
D. 混联式混合动力汽车
A. "功率端子、信号/控制端子;功率端子、信号/控制端子"
B. "功率端子、信号/控制端子;信号/控制端子、功率端子"
C. "信号/控制端子、功率端子;功率端子、信号/控制端子"
D. "信号/控制端子、功率端子;信号/控制端子、功率端子"
A. 服务空间
B. 立体空间
C. 学习空间
D. 三维空间
A. 帧-状态-音素-单词
B. 帧-音素-单词-状态
C. 帧-音素-状态-单词
D. 音素-帧-状态-单词
解析:这道题目考察的是语音识别中的基本概念和结构。我们来逐一分析选项,并理解为什么答案是A。
### 语音识别的基本概念
在语音识别中,通常可以将语音信号从微观到宏观分为几个层次:
1. **帧(Frame)**:这是最基本的单位。语音信号是一个连续的波形,为了进行处理,我们通常将其分割成短时间的片段,称为帧。每一帧通常持续20-30毫秒。
2. **音素(Phoneme)**:音素是构成语言的最小声音单位。比如,在英语中,单词“cat”可以分解为/k/, /æ/, /t/三个音素。
3. **状态(State)**:在某些语音识别模型中,状态通常指的是音素的不同发音形式或变化。比如,一个音素在不同的上下文中可能会有不同的发音。
4. **单词(Word)**:这是语音识别的宏观层面,多个音素组合在一起形成单词。
### 选项分析
- **A: 帧-状态-音素-单词**:这个选项是正确的。首先,帧是最小的单位,然后通过分析帧中的特征,我们可以识别出音素,接着音素可以组合成状态,最后形成单词。
- **B: 帧-音素-单词-状态**:这个选项不正确,因为状态通常是在音素的基础上进行的,而不是在单词之后。
- **C: 帧-音素-状态-单词**:这个选项的顺序是合理的,但状态通常是音素的不同发音形式,而不是独立于音素的层次。
- **D: 音素-帧-状态-单词**:这个选项的顺序完全错误,因为帧是最基本的单位,音素是由帧分析得出的。
### 生动的例子
想象一下,你在听一段音乐。音乐的每一个音符就像是“帧”,它们是最基本的元素。当这些音符组合在一起,就形成了旋律(类似于“音素”)。旋律在不同的上下文中可能会有不同的表现(这可以类比为“状态”),最终我们听到的完整的歌曲就是“单词”。
### 总结
因此,按照从微观到宏观的顺序,正确的排列是“帧-状态-音素-单词”,所以答案是A。
A. 便宜
B. 加工简单
C. 表面美观
D. 可塑性高
A. 30%
B. 20%
C. 10%
D. 5%


